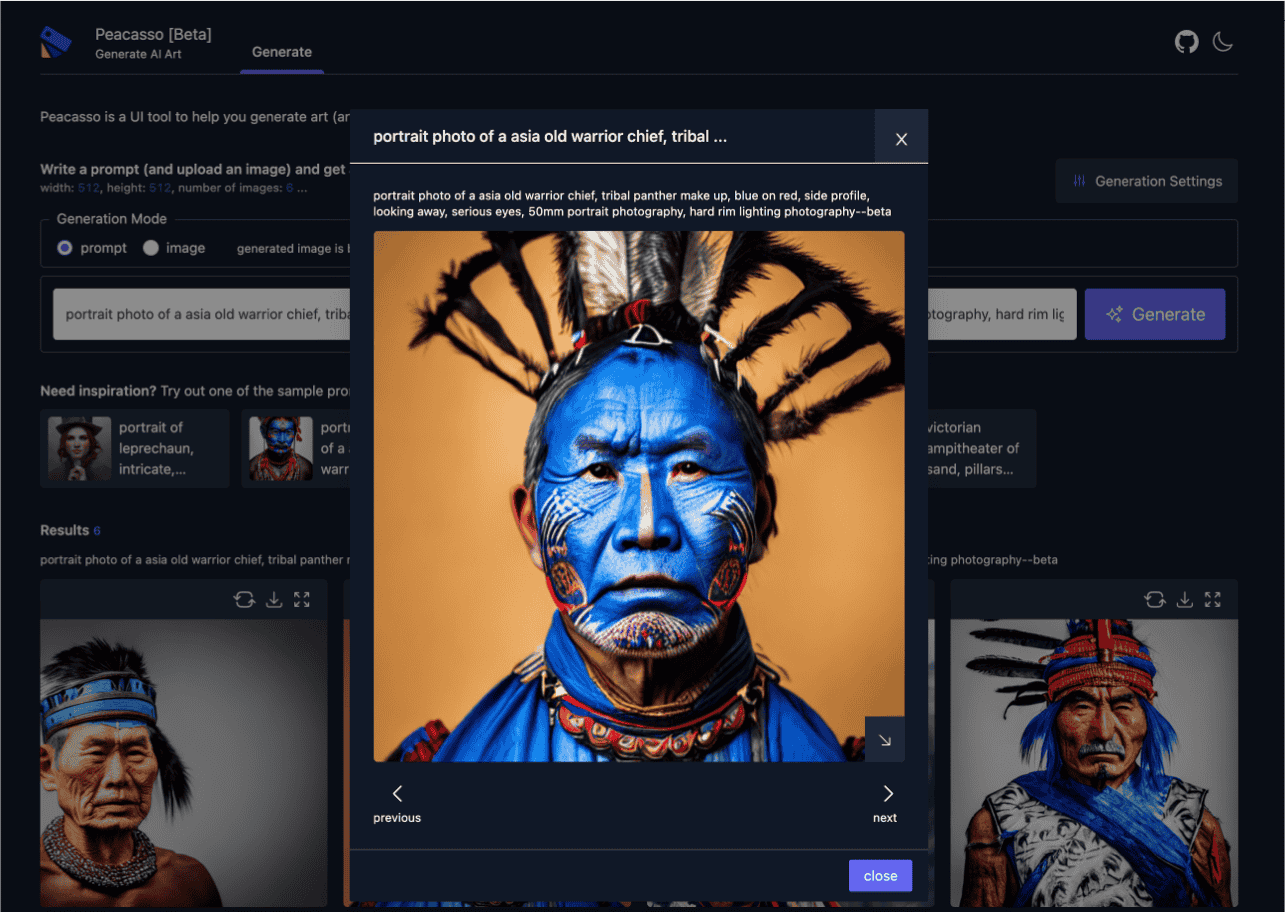
Stability AI unveiled SDXL Lightning, a streamlined version of their Stable Diffusion XL model, designed to accelerate image generation for AI applications. This update slashes processing times by up to 4x compared to the original, making it easier for developers to iterate quickly on projects.
Model: SDXL Lightning | Parameters: 1B | Speed: Up to 4x faster | Available: Hugging Face | License: Apache 2.0
Key Features and Improvements
SDXL Lightning reduces the original model's parameter count to 1 billion, enabling faster inference without major quality drops. Early testers report generation times as low as 0.5 seconds per image on standard hardware, versus 2 seconds for SDXL. This efficiency stems from distillation techniques, which compress the model while preserving 95% of output fidelity based on internal benchmarks.
Bottom line: SDXL Lightning delivers near-original quality at a fraction of the speed, empowering creators to prototype faster.
Performance Comparison with SDXL
When benchmarked on common tasks like portrait generation, SDXL Lightning outperforms its predecessor in speed metrics.
| Feature | SDXL Lightning | SDXL Original |
|---|---|---|
| Generation Time | 0.5 seconds | 2 seconds |
| Parameters | 1B | 2.5B |
| VRAM Usage | 4GB | 8GB |
| Quality Score | 95% of original | 100% |
Users note that this makes SDXL Lightning suitable for resource-limited environments, such as edge devices, without compromising on generative AI outputs.
"Detailed Benchmarks"
The model achieved a 4x speed-up in tests on an NVIDIA A100 GPU, with image fidelity scores averaging 0.92 on the CLIP metric. For specific use cases, like text-to-image tasks, it handles resolutions up to 512x512 pixels efficiently. Hugging Face model card
Practical Applications for AI Practitioners
Developers can integrate SDXL Lightning into workflows for rapid prototyping, such as in app development or real-time editing tools. It supports popular frameworks like PyTorch, with setup requiring minimal code changes from existing SDXL implementations. One insight from the community is that this model reduces costs by 50% in cloud deployments, based on AWS estimates for similar workloads.
Bottom line: By prioritizing speed, SDXL Lightning opens doors for scalable AI solutions in production environments.
In the evolving AI landscape, SDXL Lightning sets a benchmark for efficient generative models, likely influencing future iterations with even lower latency and broader accessibility for creators.




Top comments (0)