Why Qwen3-Omni?
Modern AI applications demand models that can seamlessly process and generate across multiple modalities. Qwen3-Omni addresses this need by providing native end-to-end support for text, images, audio, and video, enabling real-time streaming responses in both text and natural speech.
What It Is
Qwen3-Omni is a state-of-the-art multimodal foundation model designed to handle diverse inputs and outputs. It unifies perception and generation across modalities, delivering fluent text and natural real-time speech.
Key Features
- Native end-to-end multimodal support
- Real-time streaming responses in text and speech
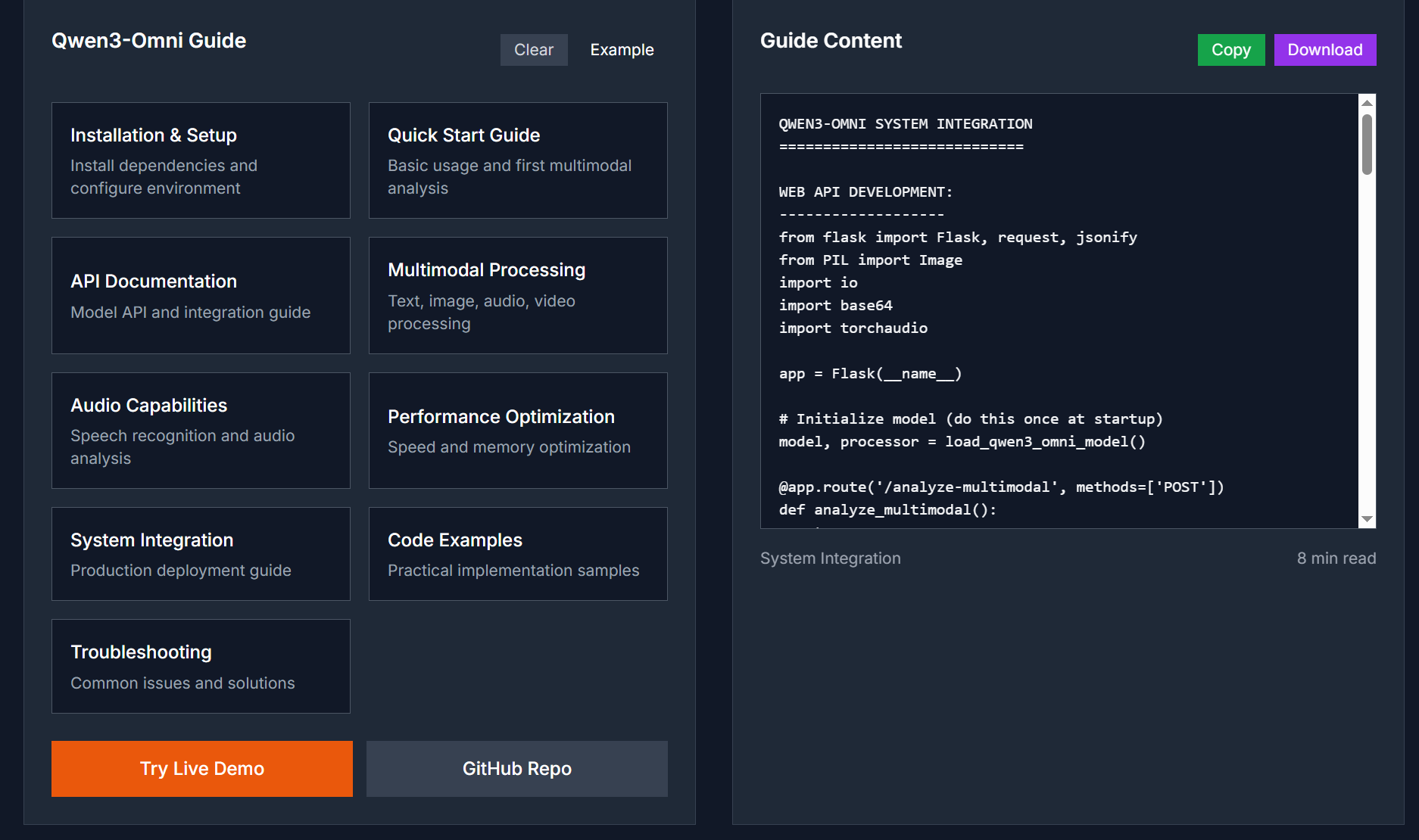
- High performance across 36 audio and audio-visual benchmarks
- Supports 119 languages for text interaction, 19 languages for speech understanding, and 10 languages for speech generation
- Fine-tunable via system prompts for behavior and persona customization
Performance
Qwen3-Omni achieves open-source state-of-the-art performance on 32 of 36 audio and audio-visual benchmarks. It outperforms models like Gemini 2.5 Pro in speech recognition and understanding tasks.
Use Cases
- Multimodal virtual assistants
- Real-time audio and video transcription
- Cross-modal content generation
- Accessibility tools for the hearing and visually impaired
- Multilingual customer support systems
Future Roadmap
- Enhanced fine-tuning capabilities for domain-specific applications
- Improved support for additional languages and dialects
- Expansion of multimodal interaction features
- Continuous performance optimization and benchmarking
Conclusion
Qwen3-Omni is a versatile and powerful multimodal model that enables developers to create advanced AI applications capable of understanding and generating across text, image, audio, and video modalities.




Top comments (0)