Why Qwen3-TTS?
Modern AI applications demand speech that is natural, fast, and expressive. Many text to speech systems compromise on latency, voice variety, or dialect support. Qwen3-TTS addresses these issues by offering low delay, multilingual output, and diverse voice synthesis.
What It Is
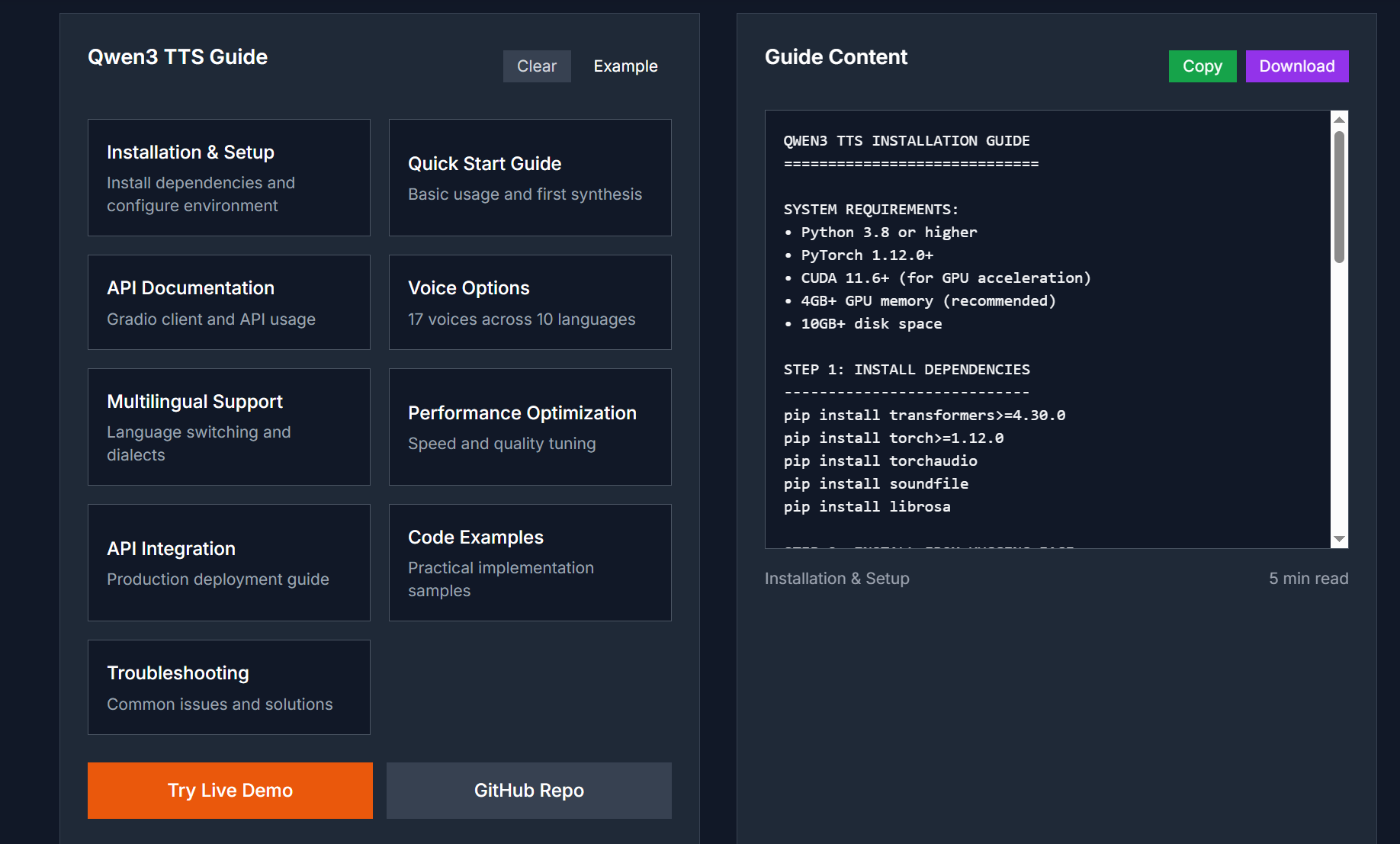
Qwen3-TTS is an advanced text to speech model on Prompt2Tool. It converts text into high quality audio with realistic expression, supporting multiple languages, voices, and dialects.
Key Features
Low latency suitable for real time interaction
Multiple voices with distinct timbres
English, Chinese, and regional dialect support
Natural prosody with emphasis and pauses
Easy integration for batch and streaming tasks
Languages and Dialects
Supports English and Chinese with authentic dialect options including Mandarin, Cantonese, and Sichuanese. This makes it ideal for assistants, narration, and multilingual content creation.
Performance
First packet latency under 100 ms
Streaming and non streaming output available
Optimized for expressive and smooth speech generation
Use Cases
Video narration and media voice overs
Chatbots and intelligent assistants
Audiobooks and e learning content
Applications requiring authentic regional dialects
Future Roadmap
Expansion of available voice styles
Emotion tags and SSML support
Personalized voice cloning features
Conclusion
Qwen3-TTS provides fast, dialect aware, expressive text to speech for modern AI solutions. It is designed for developers, creators, and businesses seeking natural voice integration.




Top comments (0)