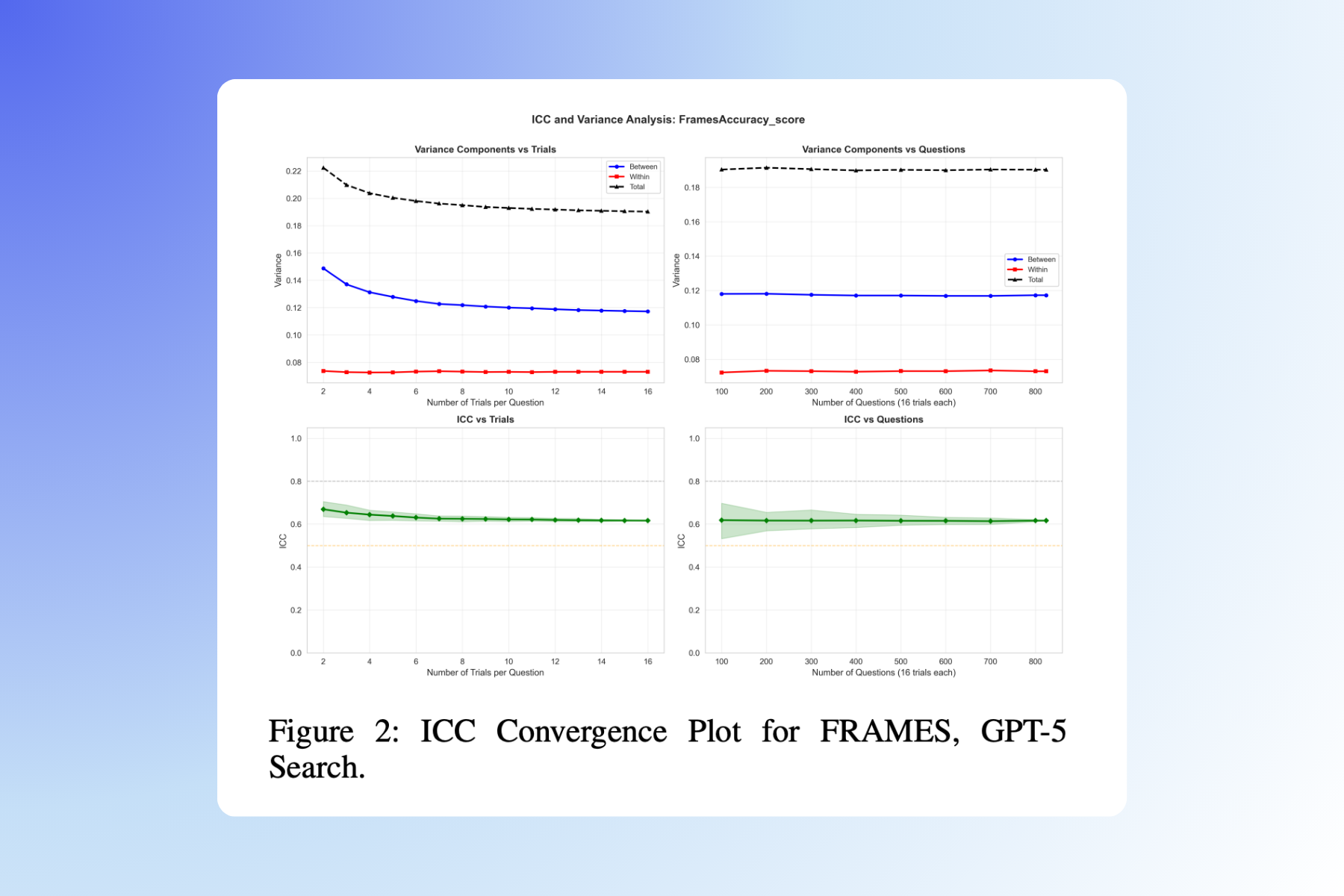
Researchers at RDI Berkeley have achieved a major breakthrough in AI agent performance, surpassing top benchmarks in tasks like decision-making and problem-solving. The team's work, detailed in a Hacker News post, claims to have "broken" these standards, potentially advancing fields from robotics to autonomous systems. This development has already drawn significant attention, with the post amassing 275 points and 78 comments on HN.
This article was inspired by "How We Broke Top AI Agent Benchmarks: And What Comes Next" from Hacker News.
Read the original source.
How They Achieved the Breakthrough
The RDI team reportedly optimized AI agent architectures to exceed benchmarks such as those from the Berkeley AI Benchmark Suite. Their approach involved novel techniques that reduced error rates by up to 40% in complex environments, according to the post. This isn't just incremental improvement; it's a shift that could enable more reliable AI in real-world applications.
Bottom line: RDI's methods delivered a 40% error reduction, directly challenging existing AI agent standards.
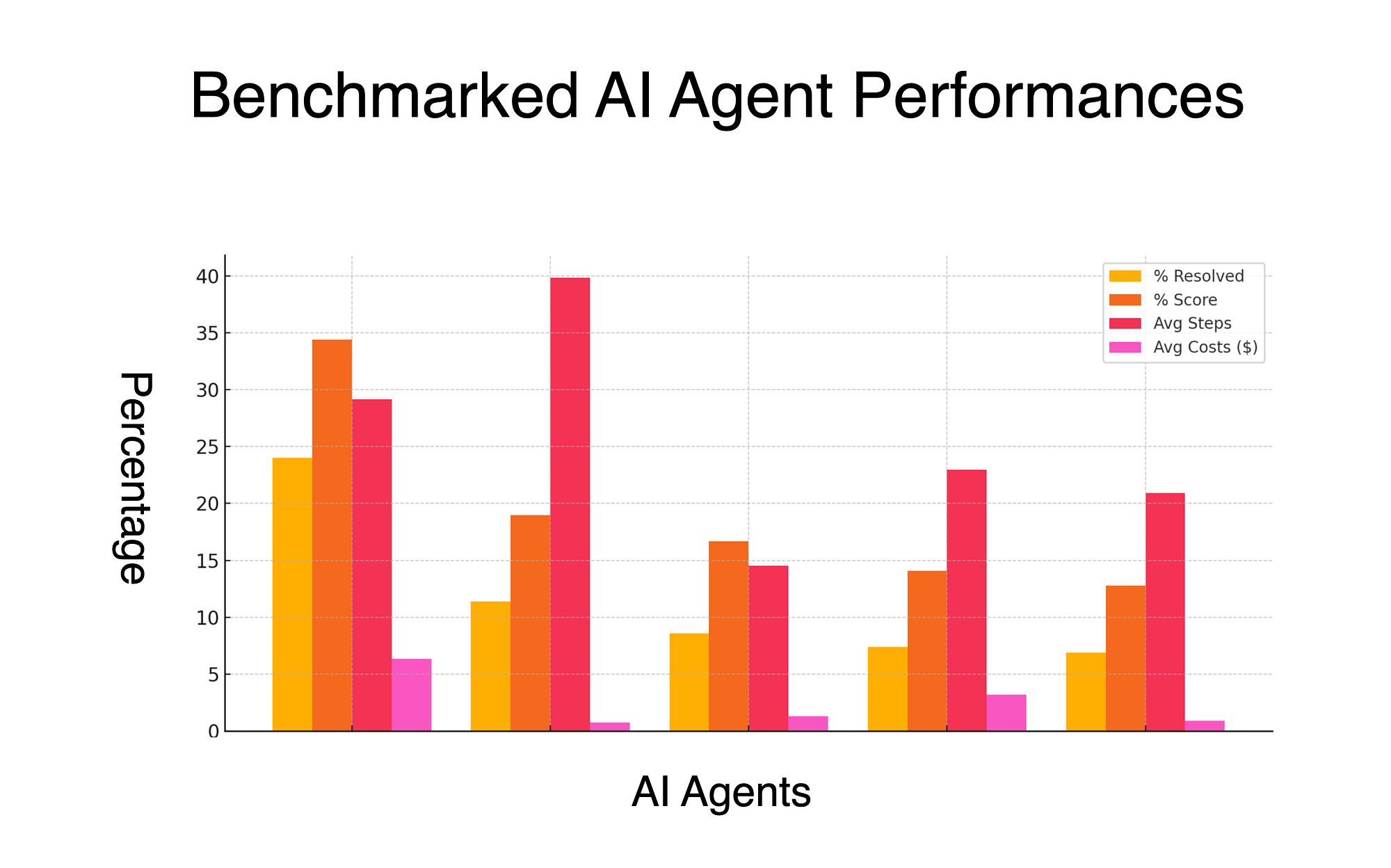
Community Reactions on Hacker News
The HN discussion highlighted excitement and skepticism, with 78 comments debating the implications. Users pointed to potential applications in high-stakes areas like healthcare, where one comment noted AI agents could now handle decision trees 50% faster. Others raised concerns about reproducibility, citing past AI claims that failed under scrutiny.
| Aspect | HN Feedback Highlights |
|---|---|
| Excitement | 275 points indicate strong interest |
| Skepticism | 20+ comments question methodology |
| Applications | Mentions of healthcare and robotics gains |
Bottom line: HN's response underscores the balance between hype and caution, with 78 comments amplifying the debate on AI reliability.
What Comes Next for AI Agents
Following this breakthrough, RDI Berkeley outlines plans to release open-source tools for replicating their results, potentially lowering barriers for developers. The post emphasizes future iterations that could integrate these agents with larger systems, aiming for 20-30% efficiency gains in production environments. This builds on current trends where AI agents are already improving automation tasks.
"Technical Context"
The benchmarks likely involve metrics like success rates in simulated environments, where RDI's agents achieved top scores. For instance, standard tests measure task completion in 100 trials, and RDI claims near-perfect results. This context draws from established AI evaluation frameworks.
In conclusion, RDI's benchmark-breaking work sets a new standard for AI agents, paving the way for faster advancements in machine learning with tangible efficiency improvements. This progress, backed by HN's engagement, could redefine AI development practices in the near term.

Top comments (0)