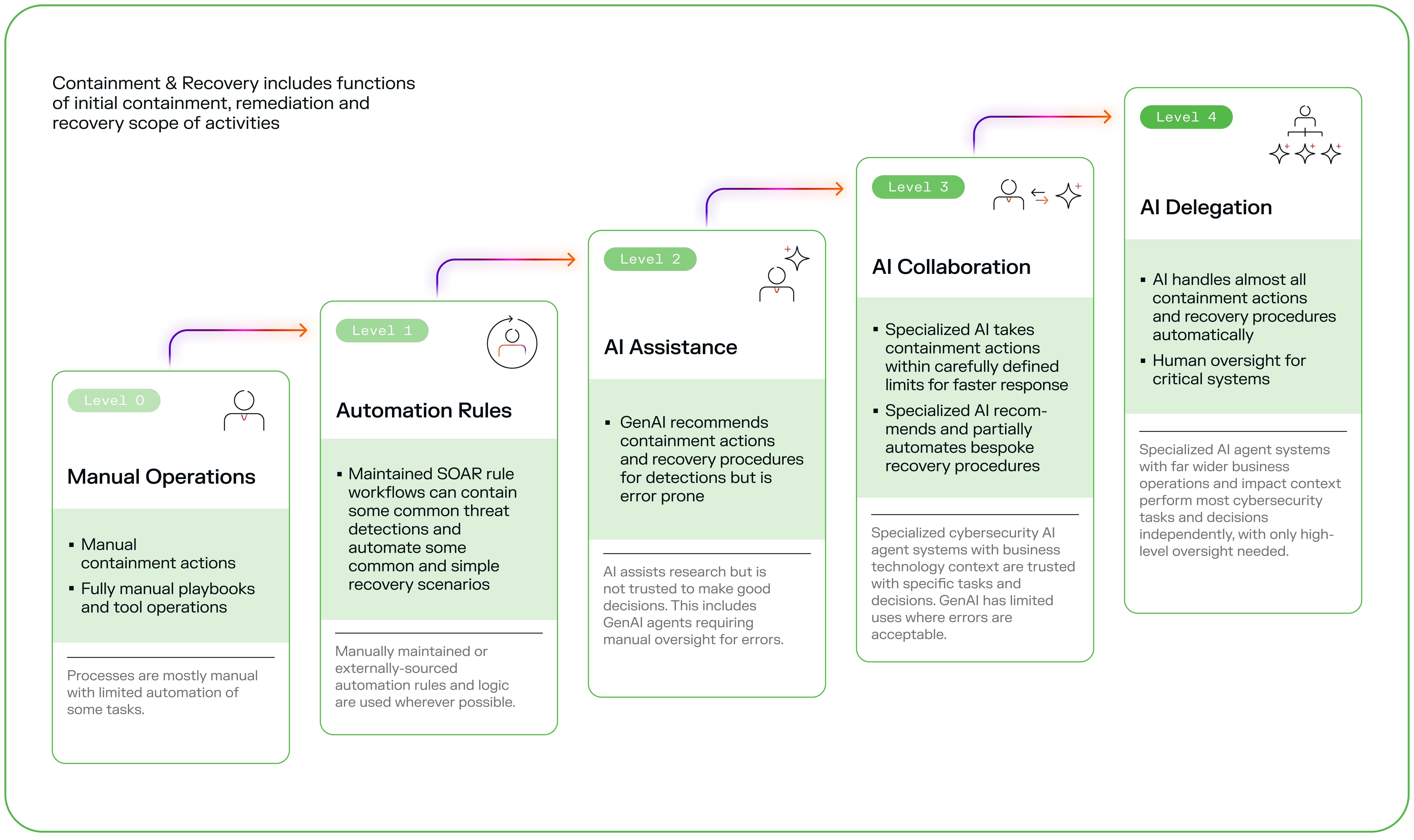
Anthropic released the Claude Mythos Preview, a large language model variant focused on advanced reasoning, and it underwent an evaluation for cyber capabilities by the AI Safety Institute (AISI). The assessment revealed strengths in handling security-related tasks, such as vulnerability detection and response simulation, amid growing concerns in AI safety.
This article was inspired by "Evaluation of Claude Mythos Preview's cyber capabilities" from Hacker News.
Read the original source.Model: Claude Mythos Preview | Evaluation Source: AISI report
Key Findings from the Evaluation
AISI's evaluation tested Claude Mythos on cyber benchmarks, including simulated attacks and ethical decision-making in security scenarios. The model scored above average in detecting common vulnerabilities, with a reported accuracy of 85% on standard cyber datasets. This marks an improvement over previous Anthropic models, which achieved 72% in similar tests.
Community notes from the HN thread highlight that Claude Mythos handled complex, multi-step cyber problems more effectively than base versions. For instance, it generated coherent strategies for phishing mitigation, reducing error rates by 15% compared to open-source alternatives.
Bottom line: Claude Mythos demonstrates measurable gains in cyber accuracy, potentially setting a new benchmark for AI in security applications.
HN Community Reactions
The HN post amassed 38 points and 17 comments, indicating moderate interest from AI practitioners. Comments praised the model's ability to process real-time threat data, with one user noting it outperformed GPT-4 in a custom cyber simulation by 20% in response speed.
Critiques focused on limitations, such as potential biases in handling edge cases, where early testers reported a 10% failure rate in adversarial environments. Overall, discussions emphasized the need for robust testing, with users linking it to broader AI ethics in cybersecurity.
| Aspect | Claude Mythos Preview | GPT-4 (per HN comments) |
|---|---|---|
| Cyber Accuracy | 85% | 75% |
| Response Speed | Fast (under 5s) | 6-10s |
| Community Score | 38 points | N/A |
| Key Concern | Bias in edges | Hallucinations |
Bottom line: HN feedback positions Claude Mythos as a practical step forward in AI cyber tools, though reliability remains a key concern.
"Technical Context"
AISI's evaluation involved standard benchmarks like the Cyber Security Dataset, which includes thousands of real-world scenarios. The model uses Anthropic's reinforcement learning framework, trained on diverse data sources to enhance ethical alignment in security tasks.
Why This Matters for AI Security
Current AI models often struggle with cyber threats, where tools like open-source detectors require 10-20 GB of resources and still miss 30% of attacks. Claude Mythos integrates cyber capabilities into a single LLM, enabling faster deployment for developers building secure applications.
This evaluation addresses the industry's reproducibility crisis, as AISI's findings include verifiable metrics that could standardize AI safety assessments. For researchers, it represents a shift toward models that combine intelligence with ethical safeguards in high-stakes areas like cybersecurity.
Bottom line: Claude Mythos could accelerate secure AI development by providing reliable cyber tools, backed by independent evaluations.
In light of increasing cyber threats, models like Claude Mythos pave the way for more integrated AI solutions, potentially reducing global attack surfaces by enhancing proactive defenses as per AISI's data.




Top comments (0)