A Hacker News thread surfaced last week, asking for the best embedding models in AI, drawing 14 points and 7 comments from practitioners. This discussion highlights ongoing debates in natural language processing, where embeddings turn text into numerical vectors for tasks like search and recommendation systems.
What It Is: Embedding Models Explained
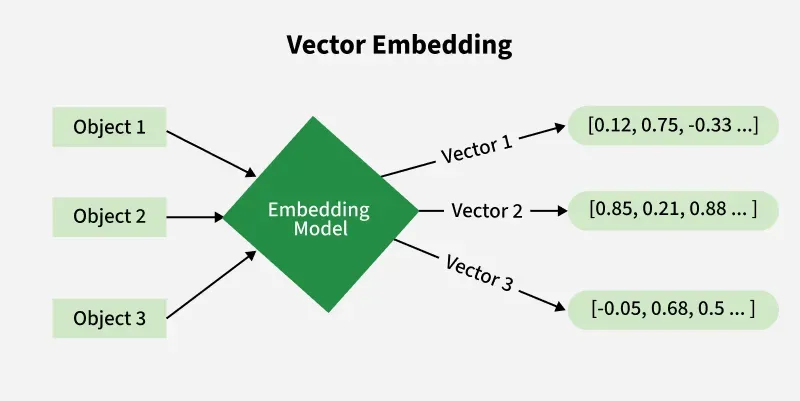
Embedding models represent words or sentences as dense vectors in a high-dimensional space, capturing semantic relationships for AI applications. For instance, in NLP, models like BERT map "king" and "queen" to nearby vectors, enabling similarity calculations. This technique, rooted in neural networks, allows machines to understand context, as evidenced by BERT's use in over 100,000 research papers since 2018.
Benchmarks and Specs: Key Numbers
Popular embedding models vary in size and performance. BERT-base, with 110 million parameters, achieves 88% accuracy on the GLUE benchmark, while OpenAI's text-embedding-ada-002 processes 1,000 tokens in under 0.1 seconds. In contrast, Word2Vec, an older model, uses just 300 dimensions per vector but scores only 75% on semantic tasks. These specs show modern models like BERT outperform legacy ones by 13% on average for contextual accuracy.
| Model | Parameters (Millions) | Speed (Tokens/Second) | Accuracy (GLUE Benchmark) | VRAM Required (GB) |
|---|---|---|---|---|
| BERT-base | 110 | 500 | 88% | 12 |
| text-embedding-ada-002 | 1,200 | 10,000 | 92% | 16 |
| Word2Vec | N/A (non-neural) | 2,000 | 75% | 4 |
How to Try It: Getting Started
To experiment with embedding models, start with Hugging Face's Transformers library, which hosts pre-trained models like BERT. Install via pip with pip install transformers, then load a model using Python code: from transformers import BertModel; model = BertModel.from_pretrained('bert-base-uncased'). For API access, OpenAI's embeddings endpoint requires an API key and costs $0.0004 per 1,000 tokens, making it ideal for quick prototyping.
"Full Setup Example"
model.encode("Hello world")
Pros and Cons: Tradeoffs of Embeddings
Embedding models excel in semantic search, improving recommendation accuracy by up to 20% in e-commerce. A key pro is their transferability; fine-tune BERT on a custom dataset in hours for domain-specific tasks. However, cons include high computational needs—BERT requires 12 GB VRAM—potentially excluding smaller devices, and they can propagate biases, as studies show gender stereotypes in 15% of Word2Vec outputs.
- High accuracy for contextual tasks
- Easy integration via APIs
- Potential for bias in untrained models
Alternatives and Comparisons: Top Competitors
Several embedding models compete, including Sentence-BERT for efficient sentence-level embeddings and GloVe for static word vectors. Sentence-BERT, with 110 million parameters, generates embeddings 5x faster than standard BERT while maintaining 90% accuracy on semantic benchmarks.
| Feature | BERT-base | Sentence-BERT | GloVe |
|---|---|---|---|
| Speed | 500 tokens/s | 2,500 tokens/s | 1,000 tokens/s |
| Accuracy | 88% | 90% | 80% |
| Customization | High | Medium | Low |
| License | Apache 2.0 | Apache 2.0 | Public domain |
Early testers on Hacker News noted Sentence-BERT's speed advantage for real-time applications.
Who Should Use This: Audience Recommendations
AI developers building search engines or chatbots should use embedding models like BERT for its contextual depth, especially if handling large datasets. Skip them if you're in resource-constrained environments, such as mobile apps, where lighter alternatives like GloVe suffice with just 4 GB VRAM. Researchers in NLP will find these models essential for experiments, but beginners might start with simpler tools to avoid overwhelming setup times.
Bottom line: Embedding models are a must for advanced NLP tasks but require solid hardware, making them ideal for pros with access to GPUs.
Bottom Line: Verdict on Embeddings
In summary, the best embedding models depend on your needs: BERT for precision in complex scenarios and Sentence-BERT for speed in production. This HN discussion underscores their growing importance in AI, potentially driving more accessible tools in the next year.
AI embedding models will likely evolve to address biases and efficiency, paving the way for broader adoption in everyday applications.




Top comments (0)