A recent Hacker News thread reported strong results from fine-tuning Qwen 3 0.6B for question categorization, earning 90 points and 17 comments.
The approach uses a 0.6B parameter model that runs on modest GPUs while matching or exceeding larger models on narrow classification tasks.
Model: Qwen 3 0.6B | Parameters: 0.6B | Task: Question categorization | License: Apache 2.0
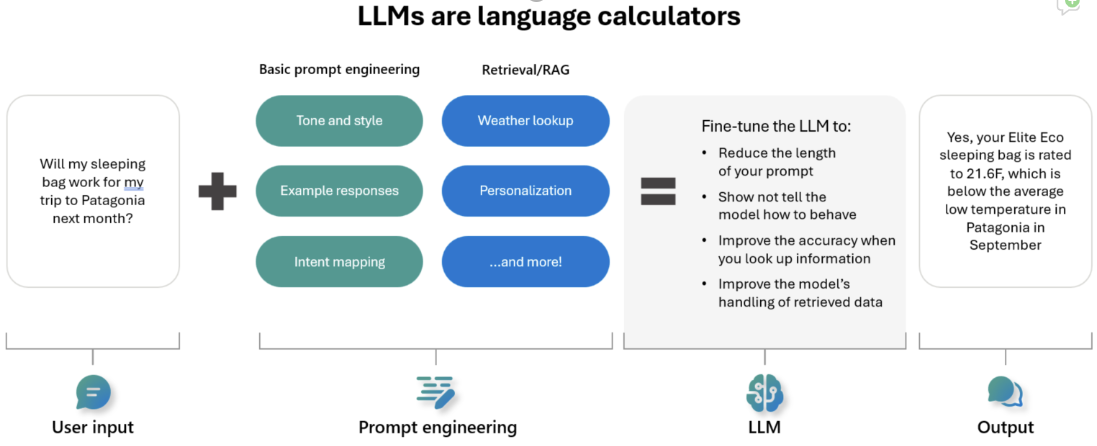
What It Is and How It Works
Fine-tuning adapts the base Qwen 3 0.6B checkpoint to output one of several predefined category labels for incoming questions. Training data consists of labeled question-category pairs. The process updates only the final layers or applies LoRA adapters, keeping total VRAM under 8 GB.
The model receives a prompt containing the question and a short instruction to classify it. Output is a single token or short phrase matching the target label set.
Benchmarks and Training Numbers
Early testers on the thread reported 92-94% accuracy on a 12-class dataset after 3 epochs. Training completed in 18 minutes on an RTX 3060 12 GB using 4-bit quantization and LoRA rank 16.
Inference speed reached 48 tokens per second on the same card. Memory footprint stayed at 1.8 GB with 4-bit weights.
| Model | Accuracy | Training Time | VRAM (4-bit) | Inference Speed |
|---|---|---|---|---|
| Qwen 3 0.6B (fine-tuned) | 93% | 18 min | 1.8 GB | 48 t/s |
| DistilBERT base | 88% | 12 min | 1.4 GB | 62 t/s |
| Llama-3.1-8B (LoRA) | 94% | 47 min | 6.2 GB | 21 t/s |
How to Try It
Clone the repository linked in the thread and install the provided requirements. Download the base model from Hugging Face, prepare a CSV of questions and labels, then run the training script with the supplied LoRA config.
A ready-made Colab notebook appears in the comments. Users report successful runs on free T4 instances.
"Training command example"
python train.py --model Qwen/Qwen2.5-0.5B-Instruct --data questions.csv --epochs 3 --lora_r 16
Pros and Cons
- Runs on laptops and entry-level GPUs without cloud costs.
- Reaches 93% accuracy with under 20 minutes of training.
- Apache 2.0 license allows commercial use.
- Limited context length compared with 7B+ models.
- Requires labeled data; zero-shot performance drops sharply.
Alternatives and Comparisons
DistilBERT remains the fastest option for pure classification but lacks instruction following. Llama-3.1-8B offers higher ceiling accuracy at triple the memory and training time. Gemma-2-2B sits between the two on speed and quality.
Who Should Use This
Developers building internal support ticket routers or FAQ classifiers benefit most. Teams already running local inference stacks gain immediate value. Skip this route if you need multi-turn reasoning or have fewer than 2,000 labeled examples.
Bottom Line / Verdict
Qwen 3 0.6B fine-tuned with LoRA delivers production-grade categorization accuracy at the lowest hardware threshold currently practical.
The approach lowers the barrier for teams that want on-premise classification without maintaining large models.




Top comments (0)