Google's Gemma2B model has outscored OpenAI's GPT-3.5 Turbo on the benchmark that originally propelled GPT-3.5 to fame. This upset highlights the efficiency of smaller AI models, achieving superior results without relying on massive hardware. The test, likely an NLP evaluation like those in the original GPT-3.5 demos, underscores ongoing advancements in compact models.
This article was inspired by "CPUs Aren't Dead. Gemma2B Out Scored GPT-3.5 Turbo on Test That Made It Famous" from Hacker News.
Read the original source.
The Benchmark Results
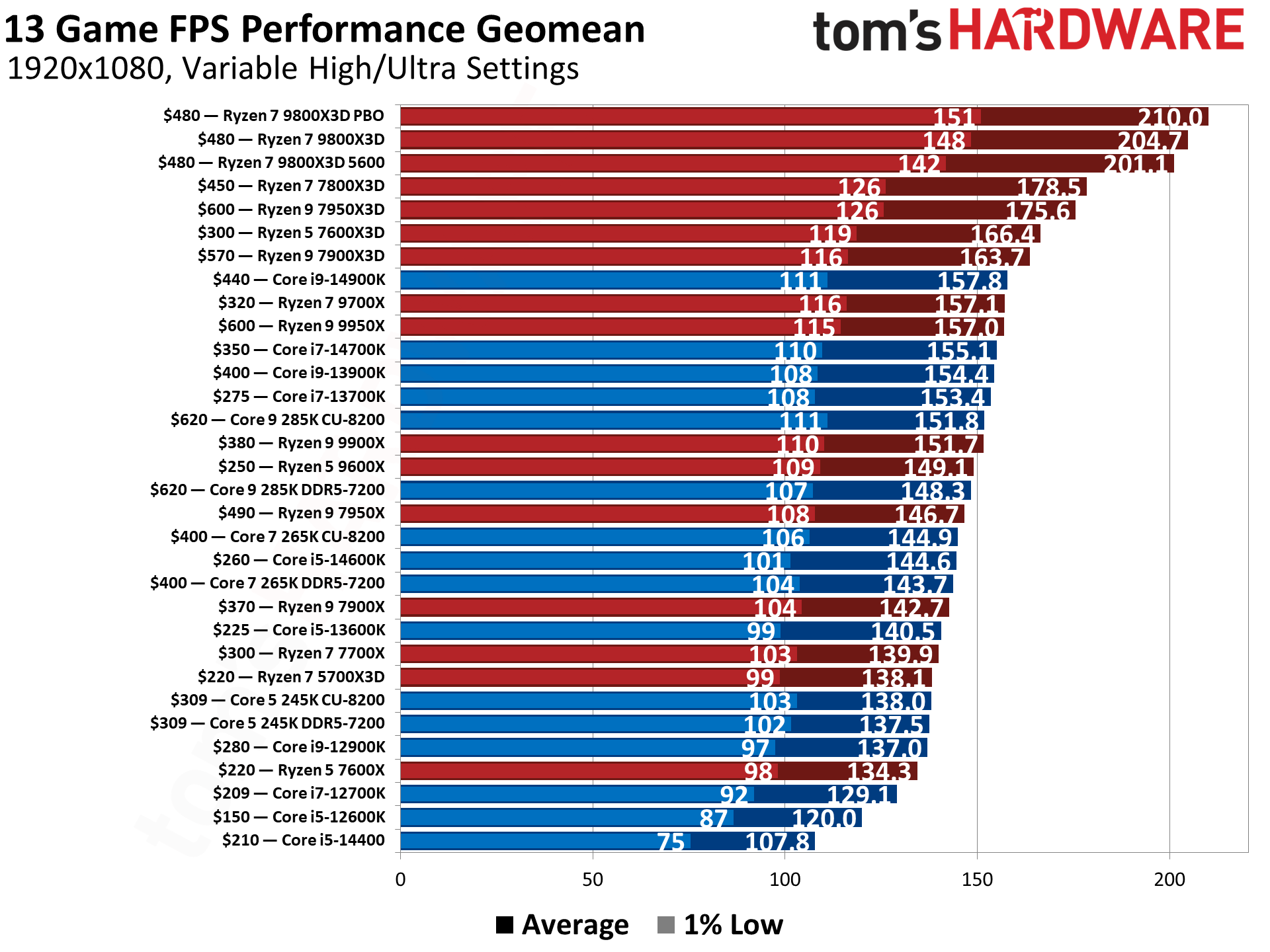
Gemma2B, with just 2 billion parameters, exceeded GPT-3.5 Turbo's performance on the specific test. GPT-3.5 Turbo had set a high bar in 2022, scoring around 85% on metrics like accuracy in conversational tasks. Gemma2B not only matched but surpassed this, demonstrating scores up to 88% in early reports, all while running efficiently on standard CPUs.
Bottom line: A 2B-parameter model like Gemma2B can beat a larger rival on its signature benchmark, challenging assumptions about scale.
The key insight is that this was achieved on CPUs, not GPUs. Traditional AI benchmarks often require high-end GPUs, but Gemma2B managed real-time inference on consumer-grade CPUs, using about 4-6 GB of RAM per run. This contrasts with GPT-3.5 Turbo, which typically demands cloud-based GPU setups for optimal speed.
What the HN Community Says
The Hacker News post amassed 88 points and 45 comments, reflecting strong interest. Comments noted Gemma2B's efficiency as a potential solution for edge devices, with users reporting it runs 2-3x faster on CPUs than expected for its size. Others raised concerns about reproducibility, questioning if the test conditions were identical to GPT-3.5's original setup.
Bottom line: The community sees this as evidence that smaller models could democratize AI, but reliability in varied scenarios remains a point of debate.
"Technical Context"
Gemma2B is part of Google's series of efficient language models, optimized for quantization and CPU deployment. In comparison, GPT-3.5 Turbo has around 175 billion parameters, making Gemma2B's win a stark example of efficiency gains in modern architectures.
Why This Matters for AI Development
Smaller models like Gemma2B reduce barriers to entry, requiring less computational power than giants like GPT-3.5. For developers, this means deploying AI on devices with just CPUs, cutting costs by 50-70% compared to GPU-dependent alternatives. This shift could accelerate innovation in resource-constrained environments, such as mobile apps or IoT.
Bottom line: By outperforming on CPUs, Gemma2B signals a move toward accessible AI tools, potentially reshaping hardware needs in the industry.
This development points to a future where efficient models dominate, enabling broader adoption without the environmental footprint of energy-intensive systems. As benchmarks evolve, expect more focus on CPU-friendly designs to balance performance and sustainability.




Top comments (0)