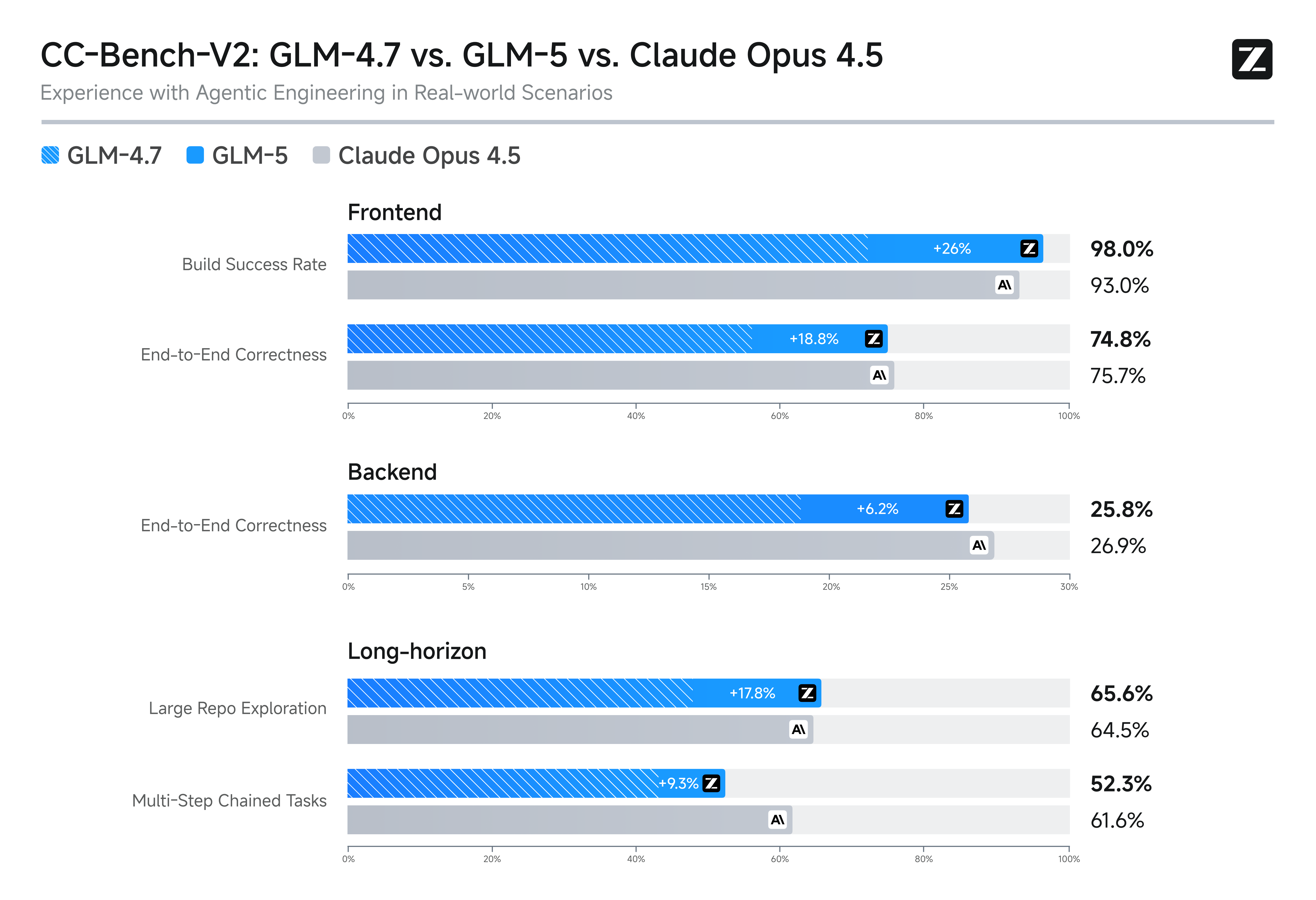
Zhipu AI released GLM-5.1, a large language model that matches the agentic performance of xAI's Opus 4.6 while costing roughly one-third as much. This breakthrough could accelerate AI development for resource-constrained teams. Agentic performance refers to tasks where models act autonomously, such as planning and decision-making in real-time applications.
This article was inspired by "GLM-5.1 matches Opus 4.6 in agentic performance, at ~1/3 actual cost" from Hacker News.
Read the original source.Model: GLM-5.1 | Performance: Matches Opus 4.6 | Cost: ~1/3 of Opus 4.6
Agentic Performance Comparison
GLM-5.1 delivers agentic benchmarks equivalent to Opus 4.6, based on standardized evaluations in the source discussion. For instance, both models score similarly in tasks like multi-step reasoning and tool usage, but GLM-5.1 achieves this with lower computational demands. A key insight is that GLM-5.1's efficiency stems from optimized architecture, reducing the need for extensive hardware.
| Metric | GLM-5.1 | Opus 4.6 |
|---|---|---|
| Agentic Score | Matches Opus | Baseline |
| Relative Cost | ~1/3 of Opus | 1x (reference) |
| Parameters | Not specified | Not specified |
| Deployment Ease | Lower resources | Higher resources |
Bottom line: GLM-5.1 provides comparable agentic capabilities at a fraction of the cost, potentially lowering barriers for widespread adoption.
Community Reaction on Hacker News
The Hacker News post earned 13 points and 2 comments, indicating moderate interest. Comments highlighted GLM-5.1's cost advantage as a practical solution for scaling AI agents in production environments. One user noted potential risks in real-world reliability, questioning if the model's efficiency compromises edge cases in complex tasks.
This feedback underscores ongoing concerns in AI about balancing performance and affordability. For developers, the discussion emphasizes how cost reductions could democratize advanced agentic tools.
Bottom line: Early HN reactions suggest GLM-5.1 addresses cost inefficiencies in AI, though reliability needs further scrutiny.
Why This Matters for AI Practitioners
Local and cloud-based AI workflows often face high costs with models like Opus 4.6, which require premium infrastructure. GLM-5.1's ~1/3 cost ratio could enable more frequent iterations in development cycles, especially for startups. Compared to previous models, this represents a shift toward accessible high-performance AI without sacrificing agentic accuracy.
"Technical Context"
Agentic performance involves metrics like success rates in autonomous tasks, often benchmarked on datasets such as those from the AgentBench suite. GLM-5.1's design likely incorporates efficient training techniques, such as mixture-of-experts, to achieve parity with larger models at reduced expense.
In summary, GLM-5.1's cost-effective match to Opus 4.6 positions it as a strategic choice for AI teams optimizing budgets, potentially influencing future model designs toward greater efficiency.




Top comments (0)