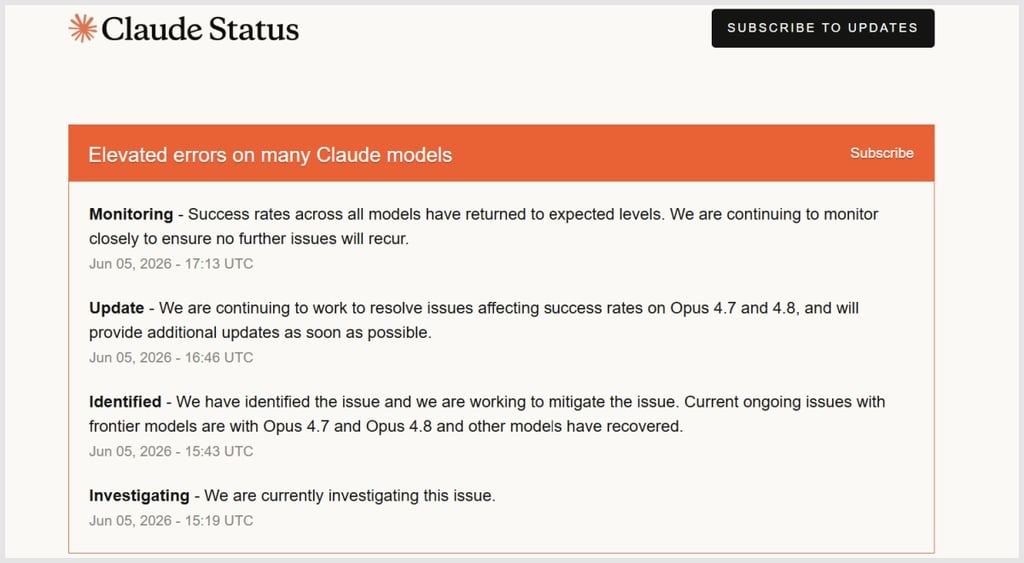
Anthropic reported elevated error rates across multiple Claude models on its official status page. The incident drew immediate attention on Hacker News, where the thread accumulated 204 points and 252 comments.
The discussion centered on error frequency, affected endpoints, and recovery timelines. Users noted intermittent failures in both API calls and web interface responses.
Incident Details
The status page listed higher-than-normal error rates spanning several model versions simultaneously. No single model was isolated; the pattern indicated a shared infrastructure issue rather than isolated code faults.
Error types included request timeouts and partial completions. Anthropic did not publish exact percentages in the initial notice.
Scale and Duration
The outage affected production workloads for an unspecified period. HN users reported repeated failures over several hours before rates began to normalize.
No official root-cause statement appeared in the first update. The incident page remained the primary source of information.
HN Community Reactions
Commenters highlighted reproducibility problems when relying on Claude for automated pipelines. Several threads questioned whether rate limits or backend load balancing triggered the spike.
- One user linked similar past incidents to GPU cluster maintenance windows
- Others compared observed error rates to OpenAI's documented 99.9% uptime targets
- Multiple reports mentioned fallback success when switching to Claude 3 Haiku during the event
Comparison with Other Providers
| Provider | Recent Outage Frequency | Typical Recovery Time | Public Status Page |
|---|---|---|---|
| Anthropic (Claude) | Multiple 2024 incidents | 2-6 hours | Yes |
| OpenAI | Quarterly major events | 1-4 hours | Yes |
| Google (Gemini) | Lower reported volume | Under 2 hours | Partial |
Anthropic's page offers clearer model-by-model status than some competitors, yet lacks real-time error-rate graphs.
Practical Workarounds
Teams running production agents added automatic retries with exponential backoff. Others routed non-critical requests to alternative models during the window.
Developers maintaining prompt libraries documented which Claude endpoints showed the highest failure rates for later analysis.
Who Should Monitor Closely
Production teams using Claude for high-volume classification or agent loops need redundant providers. Research users running batch evaluations can tolerate occasional spikes with simple retry logic.
Hobbyists and prompt engineers testing single requests faced minimal disruption.
Bottom line: The incident underscores that even frontier LLM providers experience correlated failures across model families, making multi-provider fallbacks a practical requirement rather than optional insurance.
Anthropic's transparency via a public status page sets a baseline other labs should match, yet sustained reliability metrics remain the deciding factor for production adoption.



Top comments (0)